Notebook source code:
notebooks/17_foundations__stratified_spaces.ipynb
Run it yourself on binder
![]()
Stratified spaces#
\(\textbf{Lead Author: Anna Calissano}\)
Dear learner, the aim of the current notebook is to introduce stratified spaces and its implementation within geomstats.
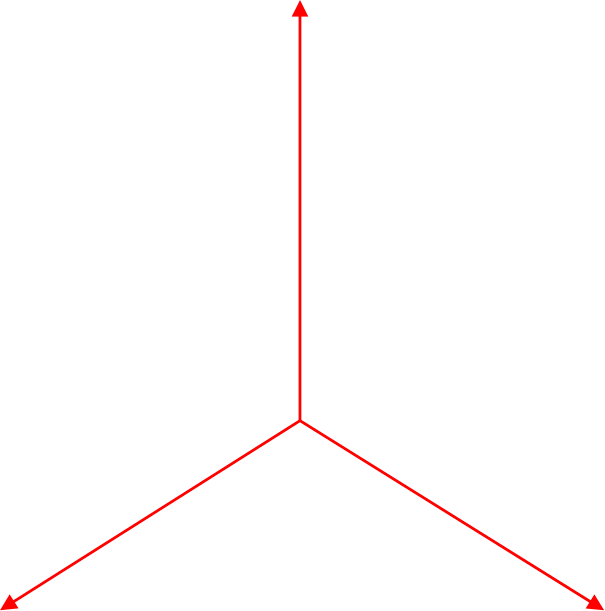
Spider#
The \(k\)-Spider consists of \(k\) copies of the positive real line \(\mathbb{R}_{\geq 0}\) glued together at the origin. Within geomstats, we defined the following:
Spider Point: a point object defining the ray and the value
Spider: the space defined by the number of rays
Spider Geometry: by chosing a metric on the rays, we can define a metric on the whole space
In [1]:
import geomstats.backend as gs
from geomstats.metric_geometry.spider import Spider
gs.random.seed(2020)
INFO: Using numpy backend
We can define a spider with \(k=3\) rays (strata) and sample two points from it.
In [2]:
spider = Spider(n_rays=3, equip=True)
spider.n_rays
Out [2]:
3
In [3]:
spider_points = spider.random_point(n_samples=2)
spider_points
Out [3]:
[r0: 10.028180271833065, r0: 11.079704435029091]
The points are represented into the SpiderPoint format, where the first input is the stratum and the second input is the value along the stratum.
In [4]:
print(spider_points[0].stratum)
print(spider_points[0].coord)
0
[10.02818027]
Given a metric \(d_{rays}\) on the strata (the rays), we can extend it to the whole space by
Given two points on the Spider, we can compute the distance between the two points as well as the geodesic between the two.
In [5]:
spider.metric.dist(spider_points[0], spider_points[1])
Out [5]:
array(1.05152416)
In [6]:
spider_geodesic_func = spider.metric.geodesic(spider_points[0], spider_points[1])
print(spider_geodesic_func(0), spider_geodesic_func(0.5), spider_geodesic_func(1))
[r0: 10.028180271833065] [r0: 10.55394235343108] [r0: 11.079704435029091]
Graph Space#
Graph Space is a space defined to describe set of graphs with a finite number of nodes which can be both node labelled or node unlabelled.
Inspired by: A. Calissano, A. Feragen, S. Vantini, Populations of unlabeled networks: Graph space geometry and geodesic principal components, MOX Report (2020)
We consider graphs as triples \(G=(V,E,a)\), where the node set \(V\) has at most \(n\) elements, and the edge set \(E \subset V^2\) has maximal size \(n^2\). The nodes and edges are attributed with elements of an attribute space \(A\), which is considered to be Euclidean, via an attribute map \(a \colon E \rightarrow A\). Here, the map \(a\) allows us to describe attributes on both edges and nodes, as we use self loop edges (diagonal elements in the graphs adjacency matrix) to assign attributes to nodes. A graph with scalar attributes is completely specified by a weighted adjacency matrix of dimension \(n\times n\), residing in a space \(X=\mathbb{R}^{n^2}\) of flattened adjacency matrices. If the attributes are vectors of dimension \(d\), the graph is represented by a tensor of dimension \(n\times n\times d\), residing in a space \(X=\mathbb{R}^{n\times n\times d}\).
In [7]:
import matplotlib.pyplot as plt
import networkx as nx
from geomstats.metric_geometry.graph_space import GraphSpace
Graph#
Consider a graph with \(n=3\) nodes and \(A=\mathbb{R}\) scalar attributes on nodes and edges. It is represented by its adjacency matrix.
In [8]:
graph_point = gs.array([[10, 3, 1], [3, 2, 4], [1, 4, 5]])
To simplify the visualization and the access to different methods, the graph can be turned into a networkx graph.
In [9]:
graph_point_nx = nx.from_numpy_array(graph_point)
edges, weights = zip(*nx.get_edge_attributes(graph_point_nx, "weight").items())
pos = nx.spring_layout(graph_point_nx)
nx.draw(
graph_point_nx,
pos,
node_color="b",
edgelist=edges,
edge_color=weights,
width=5.0,
edge_cmap=plt.cm.Blues,
)

Set of Graphs: GraphSpace#
Graphs can have different numbers of nodes and different node labels or order. We assume the existence across the populations of at most \(n\) distinct nodes and we add fictionally null nodes to smaller networks, so that all graphs can be described by a fixed-size adjacency matrix. Graph Space is initalized by the maximal number of nodes in the set.
In [10]:
total_space = GraphSpace(n_nodes=4)
Within GraphSpace, we can sample points from random adjacency matrices, we can check if the points belongs and we can return a set of adjacency matrices.
In [11]:
points = total_space.random_point(2)
total_space.belongs(points)
Out [11]:
array([ True, True])
Labelled or Unlabelled?#
Graphs can be considered labelled or unlabelled, meaning that the observation in the set can share the same nodes (labelled) or not (unlabelled). We can describe both cases into Graph Space by using a little trick.
To deal with unlabelled nodes, alignment two graphs corresponds to finding optimal permutations of their nodes. By allowing node permutation, a concept of equivalence class is introduced (i.e., every network is associated to the set of networks obtained by permuting the original one). In geometrical terms, this can be described as a quotient space obtained by applying a permutation action to the set of adjacency matrix.
In details, the group of node permutations \(T\) can be represented via permutation matrices, acting on \(X\) through matrix multiplication. The binary operation:
thus defines an action of the group \(T\) on \(X\). The obtained quotient space \(X/T\) is called graph space, and each element of \(X/T\) is an unlabelled graph \(G\), represented as an equivalence class \([x]=Tx\) which contains all the flattened adjacency matrices in \(X\) which can be obtained from \(x\) by permuting nodes. The map \(\pi \colon X \to X/T\) given by \(\pi(x) = [x]\) can be thought of as a projection of the Euclidean total space \(X\) onto the graph space \(X/T\), and the total space \(X\) plays a similar role relative to graph space, as the tangent space does for manifolds, by providing a Euclidean space in which approximate computations can be carried out and projected back onto the space of interest – in our case the graph space \(X/T\).
To deal with labelled nodes, we restrict the set of permutation matrices to the identity: \(T=\{I\}\)
Graph Space Metric#
To define a metric on graph space, we need to choose a metric on the total space. Any metric \(d_X\) on \(X\) defines a quotient pseudo-metric
on \(X/T\). Since the permutation group \(T\) is finite, \(d_{X/T}\) is a metric, and the graph space \(X/T\) is a geodesic space. In the implementation, we suppose that the default metric in the total space is the Frobenius metric between adjacency matrix.
In geomstats, we can equip the total space with a group action, and then get the corresponding quotient structure:
In [12]:
total_space.equip_with_group_action() # permutations by default
total_space.equip_with_quotient();
The graph space becomes then available under total_space.quotient and is equipped with a quotient metric.
In [13]:
graph_space = total_space.quotient
Let’s compare the difference between distances in the total and graph spaces:
In [14]:
point_a, point_b = points
dist_total = total_space.metric.dist(point_a, point_b)
dist_quotient = graph_space.metric.dist(point_a, point_b)
print(f"dist quotient <= dist total:\n{dist_quotient} <= {dist_total}")
dist quotient <= dist total:
1.3431542528099538 <= 1.4460818164862586
Graph to Graph Alignment#
The metric on Graph Space relies on the optimization along the quotient fibers. In this context the optimization problem is known as graph matching (or network alignment) and corresponds in finding a match between the two sets of nodes which minimizes the distance between the corresponding adjacency matrices. The distance function needs an aligner input, which solves the minimization problem by returning the second input graph optimally aligned. One of the available aligners are:
‘FAQ’: the Fast Quadratic Assignment Matching implemented in
scipy.optimize.quadraticassignment which is the state of the art in the matching literature based on the Frobenius norm.
The aligner algorithm can be set in the object total_space.aligner, which connects the total and the quotient spaces (it has a similar role as FiberBundle, but with less structure).
We can align a set of points using the following function, which returns the permuted graphs:
In [15]:
aligned_points = total_space.aligner.align(point=points, base_point=points)
aligned_points
Out [15]:
array([[[-0.34330033, -0.35911276, 0.25708028, 0.23632492],
[-0.14433691, -0.15890698, 0.16680305, -0.28289936],
[ 0.06142698, -0.37582122, -0.18026352, 0.45321387],
[-0.36264321, 0.0694131 , 0.47566548, 0.00336706]],
[[ 0.16766421, -0.4658085 , -0.04388063, -0.34414864],
[-0.02395103, -0.33029756, 0.39625834, -0.12660624],
[-0.12030707, 0.35831659, 0.14606105, 0.0834617 ],
[ 0.16835003, -0.32220738, 0.34924802, -0.05762742]]])
The permutations of the nodes computed by the align function are saved in the perm_ attribute. Notice that only the last run output is saved.
In [16]:
total_space.aligner.perm_
Out [16]:
array([[0, 1, 2, 3],
[0, 1, 2, 3]])
Graph to Geodesic Alignment#
In different algorithms for graphs, we need to align a graph to a geodesic. Given a point \([X] \in X/T\), a \(\gamma : \mathbb{R} \rightarrow X\), a domain \([s_{min}, s_{max}] \in \mathbb{R}\), the alignment with respect to a geodesic is performed as follow:
Sample \(s_i\in [s_{min}, s_{max}]\)
Compute \(\gamma(s_i)\)
Compute \(d_i = min_{t\in T}d_X(\gamma(s_i), t^TXt)\) is minimum
Select the \(t^TXt\) corresponding to the \(d_i\) minimum
The algorithm is described in: Huckemann, S., Hotz, T., & Munk, A. (2010). Intrinsic shape analysis: Geodesic PCA for Riemannian manifolds modulo isometric Lie group actions. Statistica Sinica, 1-58.
To perform the alignment between the geodesic and the point, we need to to define which methodology to adopt. This is specified in the set_point_to_geodesic function.
In [17]:
total_space.aligner.set_point_to_geodesic_aligner("default", s_min=-1.0, s_max=1.0)
Out [17]:
<geomstats.geometry.stratified.graph_space.PointToGeodesicAligner at 0x7540f0c8c190>
In [18]:
geodesic_func = graph_space.metric.geodesic(points[0], points[1])
total_space.aligner.align_point_to_geodesic(geodesic=geodesic_func, point=points[1])
Out [18]:
array([[ 0.09464325, -0.22793224, 0.18702875, -0.35236845],
[-0.13903918, -0.25412397, 0.29427821, -0.13448654],
[ 0.13459113, 0.03203312, 0.00102791, 0.07366849],
[ 0.19856109, -0.33860977, 0.30828458, -0.18459316]])